

|
|
||
|
Even though FMT uses Mathematica as both its run-time and user interface, the knowledge of Mathematica is not necessary to use the toolkit. Of course, the mastery of Wolfram language will help significantly, especially at more advanced level of FMT usage, but all necessary concepts are explained in this documentation.
Mathematica as a software product can be divided into two important components:
The FMT library executes at the kernel level and operates on the input that is already stripped from many of the properties of the format in which the data was introduced. For example, the following three expressions, as seen in the front-end:
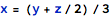


represent three different ways to code the same operation.
These three expressions can be comfortable for different groups of users - the first form is what programmers are mostly used to, as this is the form that most programming languages allow to use (it fits on a single line of code, and the line is a unit of program compilation or interpretation); the second form might be surprising to programmers, but is very convenient for mathematicians and engineers from other domains; the third form is in fact a unified form that is internally used by Mathematica - and this is the form that is visible at the kernel level. Even though the third form might look like the least readable for a human, it is the most easy to generate and process automatically.
From the point of view of the kernel (and the FMT library as well), all three forms presented above are equivalent. Or, to be more exact, there is only one form - the third one. All the other forms are just user conveniences. This unification is pervasive in Mathematica - not just single expressions, but everything, including complete functions or even whole notebooks are internally represented this way.
This distinction is very useful - the user is not constrained in how he can write code and data and can use the form that is most convenient at the given place; on the other hand, the kernel is not bothered with presentation details.
But this convenience comes with a price - some of the properties that the user might consider natural or even important are not even visible at the kernel level. In particular, there is no concept of line numbers that FMT could use when giving feedback to the user. This is visible in the second example above, which relies on the capability of the front-end to operate on 2D expressions. As a consequence, if there is an error in this particular expression, it is not possible to present it in the way that most programmers are familiar with. Moreover, the FMT library is not even able to present the code in the same way that it was written by the user.
In order to overcome this problem, FMT uses two different ways to present the code or the code locations.
For example, in the following body of a simple operation:

if there is a possible error like division by zero within the conditional part (which might happen if x is 0), the error location is shown with the help of highlighted control flow diagram:
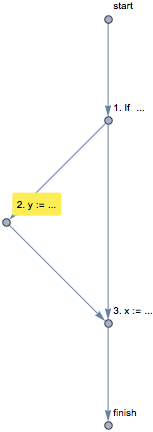
Such a diagram is usually sufficient to help the user identify the problem. The numbers 1, 2 and 3 on the diagram, followed by a short hint on the operation being performed, are statement numbers or indices, which are meant to play the same role as line numbers in traditional source code written in the ASCII file (although they are not equivalent to line numbers). The numbers are allocated sequentially and in a depth-first manner: the If statement has index 1, the instructions inside the conditional part are indexed next (so assignment to y has index 2) and the instructions that follow If continue with index 3, and so on.
Another form that is used by FMT to present code construct to the user is the tree form of the internally resolved grammar, where the same operation as above would be presented as:
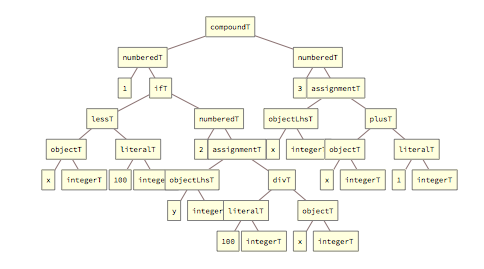
Such tree diagrams can get very complex for longer operations, but they can be manually expanded and individual elements can be repositioned with the mouse in the front-end. The tree diagrams are useful to identify grammar errors or to visualise the progression of grammar reduction steps.
The FMT library was implemented as a set of Wolfram packages and is intended to be used in the Mathematica context - for this reason the usual naming conventions of this platform apply, like all FMT function names starting from lowercase, with the exception of few symbols that fit very well into the set of already existing Wolfram constructs. All FMT names are defined within one of the FMT packages, to avoid conflicts at the level of global namespace.
The naming convention does not apply only to FMT functions, but also to the program model that is developed with the use of FMT. The following rules are highly recommended:
An important principle that should be rigorously followed when naming things in the model is to avoid the use of underscore character: _. In Wolfram, underscore (known as Blank) takes part in the pattern-matching system and its use in any of the names triggers pattern matching processing that most likely leads to surprising or incomprehensible error messages.
It might be tempting for the engineer to use the underscore in some of the names, especially those that are composed from multiple words, but it will cause troubles - and is not necessary, as the code generation engine will automatically translate multi-word names into constructs that use underscores as separators in the target programming language. For example, launchRocket in the model will be translated to Launch_Rocket if Ada is chosen as a target programming language (name translation scheme can be further customized as well).
Other conventions that need to be mentioned are related to modeling terminology used in FMT. This terminology is similar to and unifies the one used in all target programming languages, so should not be surprising for software engineers:
These terminology conventions are reflected in how main FMT modeling functions are named: declarePackage, defineDataTypes, defineDataObjects, declareOperations and finally defineOperation.
In this documentation, as well as in separate example notebooks that were created for FMT, if there is a single model created in the session, it is called sys:

This name is only conventional and nothing should prevent the user from choosing more descriptive names, especially when multiple models are being used within a single Mathematica session at the same time.
The distinction between front-end and kernel in Mathematica allows to cater to two different needs (presentation vs. computing) and it makes sense to retain this distinction in the library API.
In interactive sessions the user might want to present all results in a way that is readable and esthetic. The flow chart and grammar tree presented before show a possible way to present the data to the user. On the other hand, the user might want to automate further processing of results, or implement additional analysis, where handling of pictures would be counter-productive. For this reason, most of the checks, analyses and reports that are implemented in FMT have two APIs: one for visual presentation and one for raw data.
Those FMT functions that return raw data usually have names starting with report (like reportGrammar), whereas functions that return results in a graphical form start with show (like showGrammar). Their results are always consistent, as visual functions only format raw data they they internally obtain by calls to their raw-data counterparts.
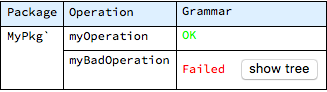
For example, the raw-data report on grammar checks for a system that has a simple package named “MyPkg`” with two operations myOperation and myBadOperation can be invoked with the following call:
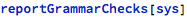

The structure returned above is a nested association - the outer association has package names as keys, and values are nested associations with results for individual operations. Thus, one operation in this system has correct grammar and the other one has errors - such a result can be captured and processed as usual in the Wolfram language.
The same report, but meant for visual or interactive presentation, can be invoked like here:
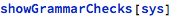

Internally, showGrammarChecks relies on reportGrammarChecks to provide raw data for formatting.
In a similar pattern, the grammar tree presented previously in a graphical form (with showGrammar), can be returned as raw data with the reportGrammar counterpart:
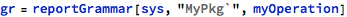

Arguably, the visual version is much easier to analyse by a human, but the raw-data version can be processed further if necessary. For example, if the user needs to focus only on literal values that are used in the given operation, he can cherry-pick them from the raw data (here captured as gr) with a standard Cases function:

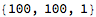
The ability to use both raw-data and graphical notations makes FMT both powerful and easy to use.
The last of the important conventions of FMT is the unified way to select packages and operations for processing.
Most of the functions that perform checks or analyses for multiple operations in the model, accept optional parameters that guide the selection of packages and operations. These optional parameters have default value All, which means that all available structures are processed:


It is possible to select some particular package for analysis:


The packageNames option above expects a list of package names, but can also accept a single value as a short-hand for the single-valued list.
Selecting operations is also possible in a similar way:
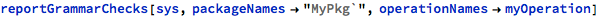

The operationNames also accepts a list or a single value.
Either option can be omitted and the scheme works for both raw-data functions as well as for graphical-formatting ones.
Previous: Installing FMT, next: Packages
See also Table of Contents.